2023.09.15 - [C/알고리즘] - 스택 응용(수식 계산)
스택 응용(수식 계산)
1. 수식표기법 (1) 중위표기법(infix notation) : 연산자를 피연산자의 가운데 표기하는 방법 => 우리가 사용하는 방식 ex) A+B (2) 후위표기법(postfix notation) : 연산자를 피연산자 뒤에 표기하는 방법 => 컴
growingupis.tistory.com
=> 해당 알고리즘의 자세한 내용은 위의 글에 기재되어있다
1-1. 스택 구현 클래스
Stack.h#pragma once #define MAX_SIZE 100 #include <memory.h> template <typename T> class Stack { private: T stack[MAX_SIZE]; int top; public: Stack():top(-1) { memset(stack, 0, sizeof(stack)); } void push(T item); T pop(); T peek(); int isEmpty(); int isFull(); void printStack(); };
Stack.cpp#include "Stack.h" #include <iostream> using namespace std; template <typename T> void Stack<T>::push(T item) { if (isFull()) { return; } else { stack[++top] = item; } } template <typename T> T Stack<T>::pop() { if (isEmpty()) { return -1; } else { return stack[top--]; } } template <typename T> T Stack<T>::peek() { if (isEmpty()) { return -1; } else { return stack[top]; } } template <typename T> int Stack<T>::isEmpty() { return top == -1; } template <typename T> int Stack<T>::isFull() { return top == MAX_SIZE-1; } template <typename T> void Stack<T>::printStack() { for (int i = 0; i <= top; i++) { cout << stack[i] << " "; } cout << endl; }
1-2. 중위표기식 => 후위표기식 변환 헤더파일
infix_to_postfix.h#pragma once #include "Stack.h" #include <string.h> #include <iostream> using namespace std; int precedence(char item) { switch (item) { case '(': case ')': return 0; case '+': case '-': return 1; case '*': case '/': case '%': return 2; } } void infix_to_postfix(char* infix, char* postfix) { Stack<char> st; int len = strlen(infix); int k = 0; for (int i = 0; i < len; i++) { char item = infix[i]; if (item == ' ') { continue; } if (item >= '0' && item <= '9') { int j = i; while (infix[j] >= '0' && infix[j] <= '9') { postfix[k++] = infix[j]; j++; } i = j - 1; postfix[k++] = ' '; } else if (item == '(') { st.push(item); } else if (item == ')') { while (!st.isEmpty()) { char data = st.pop(); if (data == '(') { break; } else { postfix[k++] = data; postfix[k++] = ' '; } } } else { while (!st.isEmpty()) { char data = st.peek(); if (precedence(data) < precedence(item)) { break; } else { postfix[k++] = st.pop(); postfix[k++] = ' '; } } st.push(item); } } while (!st.isEmpty()) { postfix[k++] = st.pop(); postfix[k++] = ' '; } postfix[k] = '\0'; }
1-3. 후위표기식 이용한 수식 계산
eval_postfix.h#pragma once #include "Stack.h" #include <string.h> int evaluate(char* exp) { Stack<int> st; int len = strlen(exp); for (int i = 0; i < len; i++) { if (exp[i] == ' ') { continue; } if (exp[i] >= '0' && exp[i] <= '9') { int j = i; int val = 0; while (exp[j] >= '0' && exp[j] <= '9') { val *= 10; val += (exp[j]-'0'); j++; } i = j; st.push(val); } else { char item = exp[i]; int data1= st.pop(); int data2 = st.pop(); switch (item) { case '+': st.push(data1 + data2); break; case '-': st.push(data2 - data1); break; case '/': st.push(data2 / data1); break; case '*': st.push(data2 * data1); break; case '%': st.push(data2 % data1); break; } } } return st.pop(); }
1-4. main함수
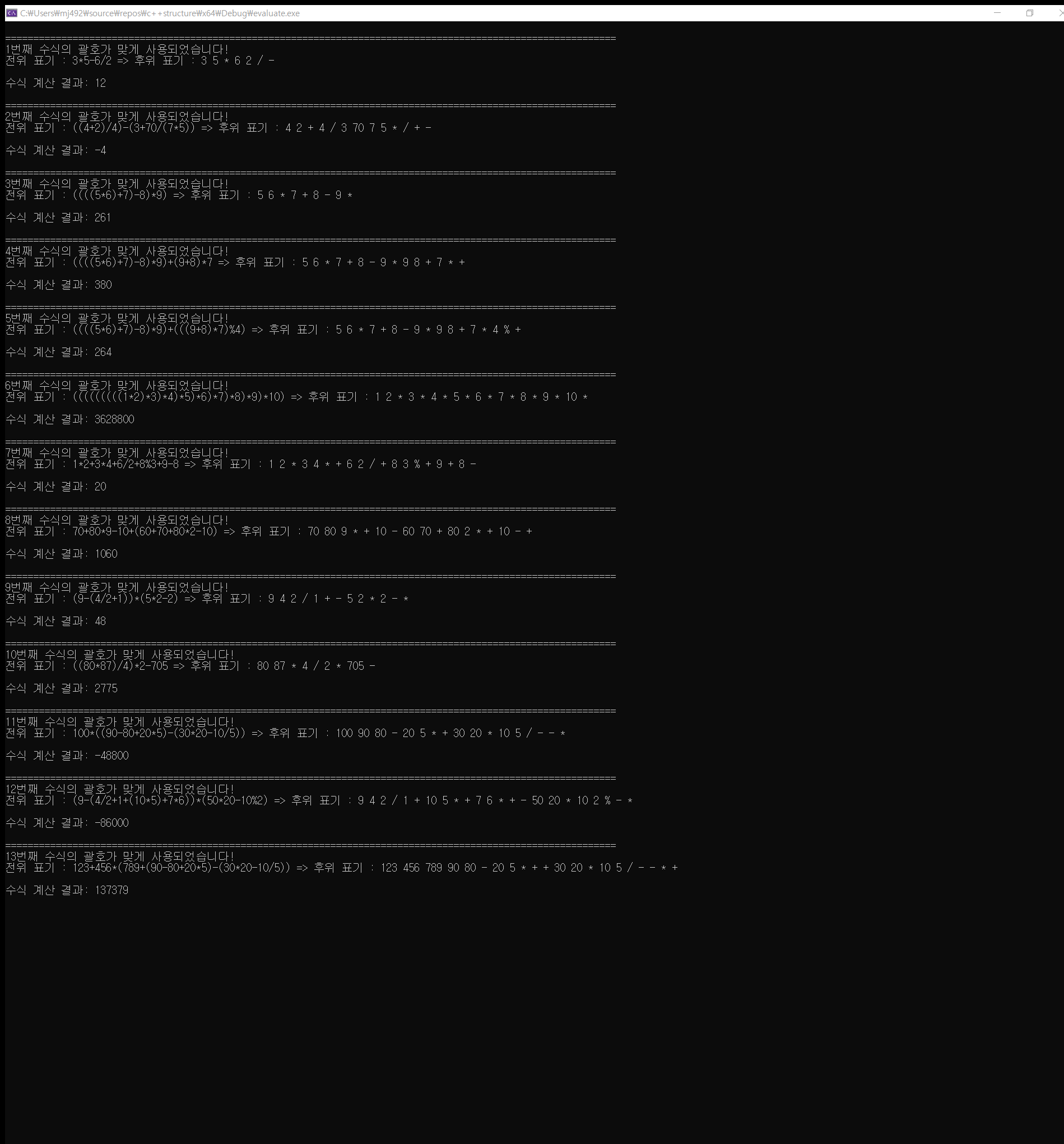
main.cpp#include <iostream> #include <string.h> #include <memory.h> #include "Stack.h" #include "Stack.cpp" #include "evaluate.h" #include "infix_to_postfix.h" #define MAX_SIZE 100 #define TRUE 1 #define FALSE 0 using namespace std; int testPair(char *exp) { int len = strlen(exp); Stack<char> st_char; for (int i = 0; i < len; i++) { if (exp[i] == '(' || exp[i] == '{' || exp[i] == '[') { st_char.push(exp[i]); } else if (exp[i] == ')' || exp[i] == '}' || exp[i] == ']') { if (st_char.isEmpty()) { return FALSE; } else { char data = st_char.pop(); if ((data != '(' && exp[i] == ')') || (data != '{' && exp[i] == '}') || (data != '[' && exp[i] == ']')) return FALSE; } } } if (!st_char.isEmpty()) { return FALSE; } else { return TRUE; } } int main() { char infix_expr[13][80] = { "3*5-6/2", "((4+2)/4)-(3+70/(7*5))", "((((5*6)+7)-8)*9)", "((((5*6)+7)-8)*9)+(9+8)*7", "((((5*6)+7)-8)*9)+(((9+8)*7)%4)", "(((((((((1*2)*3)*4)*5)*6)*7)*8)*9)*10)","1*2+3*4+6/2+8%3+9-8", "70+80*9-10+(60+70+80*2-10)", "(9-(4/2+1))*(5*2-2)", "((80*87)/4)*2-705", "100*((90-80+20*5)-(30*20-10/5))", "(9-(4/2+1+(10*5)+7*6))*(50*20-10%2)", "123+456*(789+(90-80+20*5)-(30*20-10/5))", }; char postfix_expr[MAX_SIZE]; for (int i = 0; i < 13; i++) { if (testPair(infix_expr[i])) { printf("\n============================================================================================================="); printf("\n%d번째 수식의 괄호가 맞게 사용되었습니다!\n", i + 1); memset(postfix_expr, 0, sizeof(postfix_expr)); infix_to_postfix(infix_expr[i], postfix_expr); printf("전위 표기 : %s => 후위 표기 : %s \n", infix_expr[i], postfix_expr); printf("\n수식 계산 결과: %d\n", evaluate(postfix_expr)); } else { printf("수식의 괄호가 틀렸습니다!\n"); } } getchar(); return 0; }
2. 주의사항
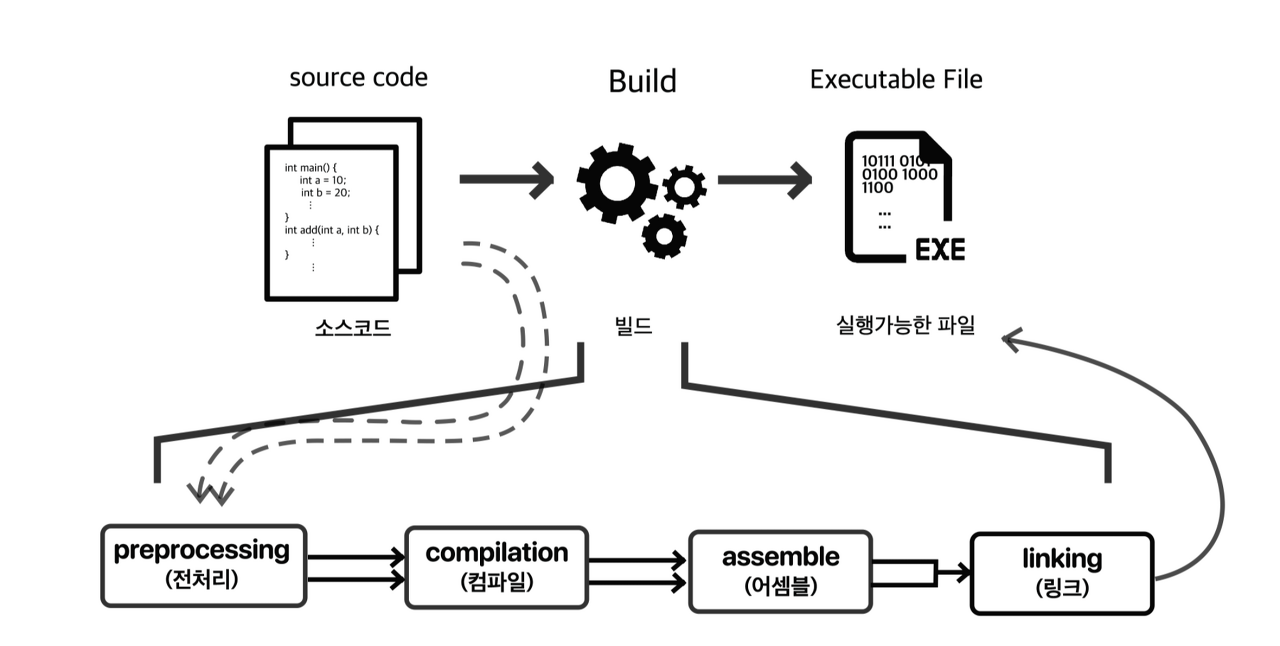
2-1. 컴파일 과정
→ 인간이 이해할 수 있는 언어로 작성된 소스 코드를 CPU가 이해할 수 있는 언어로 변환하는 작업
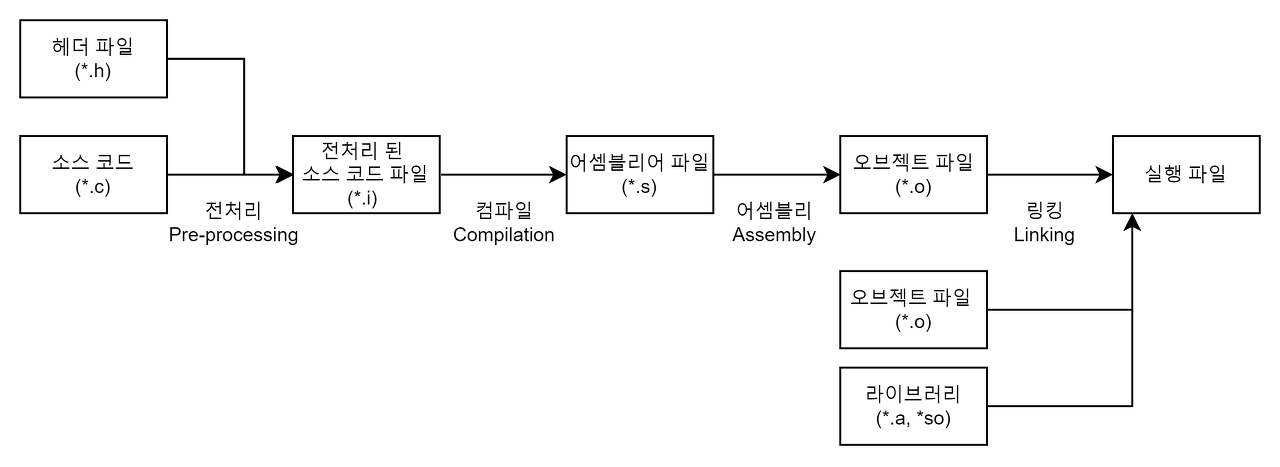
2-1-1. 전처리 과정
: 전처리기를 통해 소스 코드 파일을 전처리된 소스 코드 파일로 변환
- 주석 제거
: 소스 코드에서 주석을 전부 제거 (컴퓨터가 알 필요 x) - 헤더 파일 삽입
: #include 지시문을 만나면 해당하는 헤더 파일을 찾아 헤더 파일에 있는 모든 내용을 복사해서 소스 코드에 삽입
: 헤더파일은 컴파일되지않음
: 헤더파일에 선언된 함수 원형은 후에 링킹 과정을 통해 실제로 함수가 정의되어 있는 오브젝트 파일(컴파일된 소스코드파일)과 결합 - 매크로 치환 및 적용
: #define 지시문에 정의된 매크로를 저장하고 같은 문자열을 만나면 #define 된 내용으로 치환한다. 간단하게 말해 매크로 이름을 찾아서 정의한 값으로 전부 바꿔준다.
2-1-2. 컴파일 과정
: 컴파일러를 통해 전처리된 소스 코드 파일을 어셈블리어 파일로 변환
- 언어 문법 검사
- static한 영역(Data, BSS 영역)들의 메모리 할당 수행
2-1-3. 어셈블리 과정
: 어셈블러를 통해 어셈블리어 파일을 오브젝트 파일로 변환하는 과정
2-1-4. 링킹 과정
: 링커를 통해 오브젝트 파일들을 묶어 실행 파일로 만드는 과정
: 이 과정에서 오브젝트 파일들과 프로그램에서 사용하는 라이브러리 파일들을 링크하여 하나의 실행 파일 생성
2-2. 컴파일 역할
- 문법 체크 + staitc 한 영역들 메모리 할당
- 컴파일러는 파일 단위로 컴파일 하기에 소스코드마다 독립적이기에 기존엔 헤더파일 이용
(각각의 cpp 파일들이 독립적으로 컴파일 된 후 컴파일이 완료된 같은 프로젝트 내 cpp 파일들끼리 링킹) - 헤더파일은 컴파일 하지 않으며 cpp 파일에 include한 헤더 파일 내용이 복사됨
(함수만 선언되어 있는 헤더파일은 "나중에 이런 함수가 나올거야~"라고 알려주는 역할만) - 선언만 하고 사용하지 않으면 obj 파일을 만드는 과정에서 해당 파일은 제외시킨다
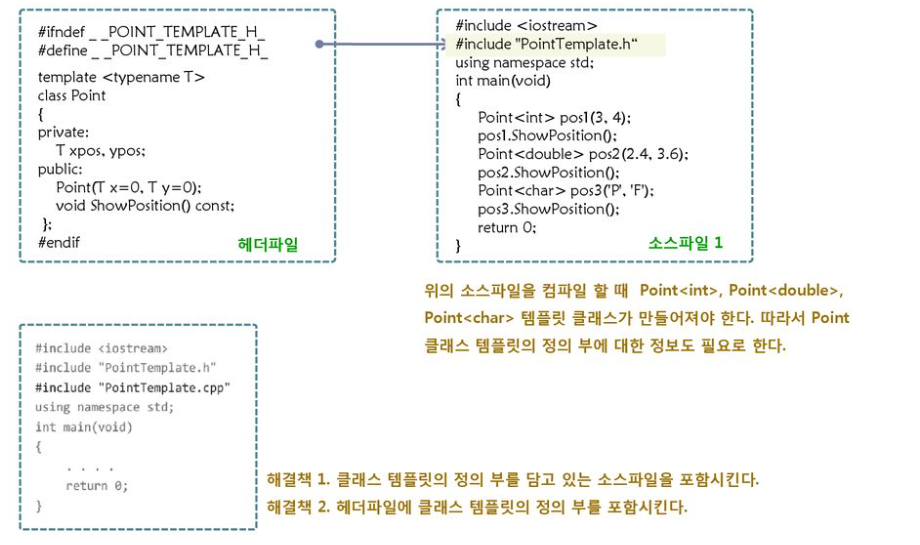
2-3. 클래스 템플릿의 헤더파일과 cpp파일을 분리할 경우엔 조심해야한다
=> 컴파일시 메모리를 정의하기위해선 구체적인 자료형을 알아야 얼만큼 메모리 할당할지 알 수 있는데 cpp파일엔 템플릿 타입만 있기에 어느정도로 할당해야할지 알 수 없기에 메모리에 할당되지 않음
(이때, main.cpp에서 헤더파일을 include하고있어 cpp내의 함수의 존재는 알고 있기에 컴파일 에러가 아닌 링킹 에러발생)
2-3-1. 해결방법
- 클래스 템플릿의 정의 부를 담고 있는 소스파일 포함
- 헤더파일에 클래스 템플릿의 정의 부 포함

'C++ > 자료구조' 카테고리의 다른 글
| [C++]AVL Tree (0) | 2023.12.07 |
|---|---|
| [C++]Reverse doubly linked list with sentinel nodes (0) | 2023.11.29 |
| [C++]Doubly linked list with sentinel nodes (1) | 2023.11.29 |
| [C++]원형큐 (1) | 2023.11.14 |
| [c++]스택 (0) | 2023.11.13 |


